Moritz Halbritter's Personal Blog


The project I’m currently working on at work uses a MSSQL database in production. Since then I have learned a lot of things, which I want to summarize here.
First: Name every unique constraint, foreign key or default constraint (yes, a DEFAULT clause on a column in MSSQL creates a constraint). If you don’t name your constraint, MSSQL will
auto-generate a name for it, and this generated name is not deterministic. You also can’t drop constraints easily if you don’t know their names (I’ll come back to that later).
When tuning database performance, take a look at covering indices. Every table in MSSQL has a primary key (covered by the clustered index) and 0 or more secondary indices (unclustered indexes). These secondary indices don’t store the page of the actual table data on the leaf node level, but a reference to the primary key. Looking up a row using a secondary index is a two-step process: use the unclustered index to find the primary key and then use the primary key in the clustered index to find the actual table data.
You can skip the second step by using covering indices. When creating the index you can specify which columns are indexed and which are covered by the index. The indexed columns are used to search the index tree, and the covering columns are stored in the leaf node of the index. When selecting a column which is covered by a covering index, the beforementioned second step (search the data via the clustered index) isn’t needed anymore. You can read more about that in this article.
Regarding indices: Did you know that indices can fragment? That means that an index is spread out over multiple pages. Defragmenting can compact them and can help to bring them back up to speed, see this article for details.
MSSQL server tracks a lot of statistics for the executed queries, their runtime, I/O cost and the like. You can, for example, find the slowest queries by executing a SQL script. This can even be done by a background job and could automatically notify you if their are a lot of slow queries. You can find more about it here. It’s also a great data source to visualize on your monitoring dashboards.
And now, my favorite finding - take a look at this graph, screenshotted from production:
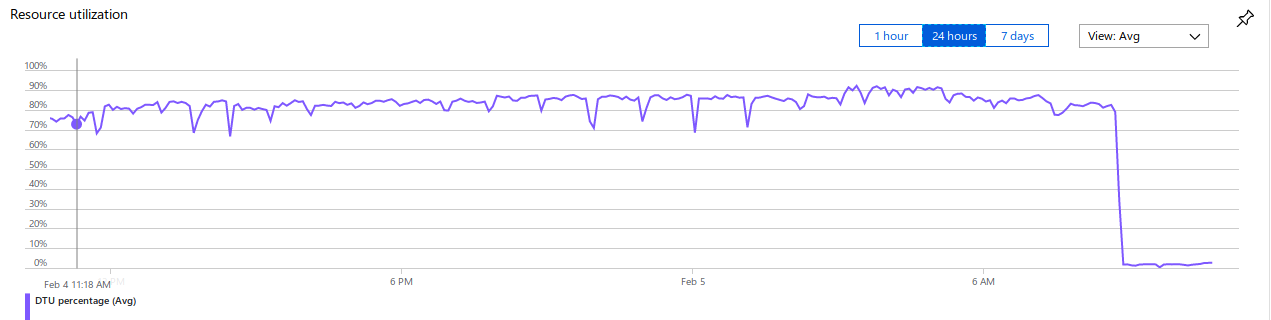
Want to guess what that steep drop was? Maybe some kind of routing problem so that no traffic hit the database anymore? A crash of the application server? Added a missing index?
This drop has been caused by a database migration which changed all CHAR, VARCHAR and TEXT columns to their unicode pendants NCHAR, NVARCHAR and NVARCHAR(max). Seriously, one of
my coworkers found this and I still can’t believe it - all the CPU cycles in the database were wasted converting text around. After all columns have been changed to unicode, the database is
twiddling its thumbs. Whole cause of the problem is that the collation of the database was some strange WIN-something encoding and we’ve been using the JDBC driver for MSSQL, whose encoding is by default some unicode encoding. Now the MSSQL server has to convert big parts of the queried
tables to unicode and this eats up a lot of CPU cycles. Apparently the default encoding of a MSSQL server, even when using the Azure Cloud, isn’t UTF-8 or some other unicode encoding. In 2019.
Best part: When analysing why those queries are so slow, you won’t find collation conversion in the query plans, at least not when you use the SQL server studio - because the collation of the SQL server studio is the same as in the database, so no conversion takes place and strangely the queries are fast again. Also the Azure SQL dashboard, which gives you hints about missing indices and stuff, DOESN’T MENTION THIS AT ALL. Fair enough, it’s mentioned in the documentation - “If using a lower version of the SQL Server Database Engine, consider using the Unicode nchar or nvarchar data types to minimize character conversion issues.” - but maybe it should have been made bold if it has that much of an impact? And what is a lower version of the SQL Server Database Engine? I’m using the one from Azure Cloud, and one of the reasons is that I get the latest and greatest. This is just dumb.
We fixed the CPU hog by converting all the columns to the unicode datatypes. Now the driver and the table used the same collation and the CPU usage dropped by a huge margin - from 80% to 4% on average. We even added a unit test which looks for non-unicode columns in the migration scripts and breaks the build if it finds one.
And another fun story regarding unicode: you can’t use a simple ALTER COLUMN to change the column to unicode, because you can’t alter columns which are affected by constraints. And good luck dropping them when you don’t know the name of the constraint.
We first had to standardize the constraint names in a migration (by selecting from SYS.CONSTRAINTS and consorts), then drop the constraints, then change the columns to unicode and then reapply the constraints. All while holding a writer lock to
prevent constraint-violating new data to enter the table from other writers. I really can’t recommend that, so please use NVARCHAR from the beginning. Or change the collation of the whole database to unicode.
That’s it, I hope you have learned something. I definitely have.